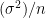Wasn’t planning a post, but it isn’t right to ignore crying children.
Wasn’t planning a post, but it isn’t right to ignore crying children.
#GiletteAd #toxicmasculinity
Wasn’t planning a post, but it isn’t right to ignore crying children.
#GiletteAd #toxicmasculinity
I loved watching Alexandria Ocasio-Cortez dance. The very fact that people thought it could be used as a smear is a reminder of how little women can do without ‘destroying our character’ or ‘being immoral’. Well, the future is dancing. 

Predicting who survived the Titanic is a well-known machine learning competition on Kaggle.
The problem provides data for each of the passengers on the Titanic, their Age, sex, the class they travelled in, the port they embarked from, the fare they paid for their ticket, the number of family members they had travelling with them etc and requires us to build a model to predict whether the passenger survived.
I started out with it as a beginner to competing in Kaggle, and I used a tree based, ensemble model in my solution as they are well known to give good results in machine learning competitions. In particular, gradient boosted machines like xgboost and lightgbm work very well with tabular data.
In this post, I am not delving into exploratory data analysis for the problem because it has been done really well by a lot of datascientists, I’ll link to a few of them here. Instead I will talk about how I started off by heavily overfitting my model and how using early stopping with LightGBM helped me get a good fit and score within the top 8% of submissions. There were a couple of places where I felt I could squeeze out a little more accuracy, but at some point we need to move on and learn more.
What is LightGBM ?
LightGBM is an ensemble model of trees (weak learners) which uses gradient boosting to form predictions. You can learn more about gradient boosted machines, including xgboost on Statquest Josh Starmer’s amazing youtube channel. Here’s the link to the original LightGBM paper.
To summarize, gradient boosting uses a series of trees. First, a base learner makes a single prediction for the entire dataset, and then each tree that comes after builds on the residuals (errors) of the previous tree. A constant learning rate is used to proportionately add up the predictions from each of the trees.
Gradient boosting is an excellent technique that has reaped great results in the few years since its inception. However, it is prone to over fitting. LightGBM provides an array of techniques to prevent overfitting. Eg: restricting the depth of each tree, the number of leaves in the tree, the number of trees in the model, the number of bins over which efficient splits are searched for etc.
When I built my model, I realized that the Titanic dataset was inherently noisy, there is no way the data could give a perfect prediction of who survived the disaster, luck invariably played a factor. I knew that it was likely my model would fit noise. Hence I used many of the hyperparameters to perform a gridsearch within cross-validation folds. However, I wasn’t reaching a satisfactory accuracy. That is when I realized, that I was building at least 50 trees in each of my models. The default for the number of trees parameter was 100 and my grid was searching among 50, 100, 150 trees. It turns out I needed way fewer trees! I wouldn’t have realized this from my grid search alone. This is where early stopping comes into play.
Early stopping essentially tunes the number of trees/number of iterations parameter for you. The crux of the technique is, LightGBM after asking for a validation dataset, offers to stop building more trees once the metric of interest (accuracy in this case) stops showing an improvement after a specified number of iterations. The icing on the cake is, early stopping also returns the best iteration (number of trees for which the validation set gave the best metric score) even if this iteration happened earlier than the number of iterations required to trigger early stopping. So, if I had set early stopping to 100 (like I did) LightGBM would perform 100 iterations for sure before invoking early stopping, that is stopping the process when improvements fail to occur. However, if the best iteration was at 20 trees. LightGBM still stores this result and lets me know!
Through this, I realized that I was heavily overfitting my model and with a large enough learning rate, I needed only two or three trees! My dataset was indeed much smaller (892 rows) than what LightGBM was built for. Once I severely cut down the number of trees, I got a greater than 80% accuracy in the contest and was among the top ~8% submissions.
My code is available here on github.
You can see in the figure below, how the training set accuracy keeps increasing with the number of trees, but the cross validation accuracy drops steeply after the first few trees. This is classic overfitting, a machine learning algorithm fitting to noise and thus giving poor generalization.
I hope you can learn from my experience.


The same graph as above with an untruncated axis, That little decline you see in the crossvalidation dataset, takes you several thousand points below on the leaderboard 😀
— author, Gowri Thampi

I often hear of denialism dressed up as skepticism, such as “I’m a climate change skeptic“’ or of late “I’m a COVID19 skeptic“’, but no, that’s not skepticism, that’s denialism, there’s no better way to put it. I enjoy statistics, I try to live as far as possible, by evidence-based reasoning, but I’m human, I’m prone to pet theories and preconceived notions like anyone else. I found great solace in Bayes’ theorem in giving me science and philosophy to balance out my human failings with my desire for facts and reason. Today I want to share this with you.
Frequentist statistics looks at a bunch of observations and make an inference about them. The null hypotheses usually go with the status quo. We humans though have preconceived notions. I’m convinced that my dog is giving me the cold shoulder because I petted another one first, I have these feelings without knowing anything about the research into animal behavior. Are dogs really capable of such thought? If scientists provide me with evidence to the contrary, should I not change my mind, despite my strong internal feelings? Bayes’ theorem is more than a formula in a textbook, the very idea of rationality and changing one’s mind based on the evidence presented, is baked into it. The formula at its simplest derives very quickly from well-known laws of conditional probability.

That is the formula, where A and B are two events. P(A) and P(B) are the probabilities of occurrence of events A and B respectively. P(A|B) is the probability of event A occurring given event B occurred and P(B|A) is the probability of event B occurring given event A occurred. The beauty of Bayes’ theorem is that you can think of the formula this way.

The prior represents your belief that A will occur (or that A is true) before being presented the evidence, the event B. P(B|A) is the likelihood of the evidence occurring if A is true, and P(B) is the overall probability of the evidence occurring. P(A|B) is how you revise your estimate that A is true, given the new evidence. Not obvious? let’s talk of a little example.
Your friend has a coin, he claims it is a loaded coin, and using it will give you an edge if you call heads. He says this coin will turn up heads, 75 percent of the time. You don’t really believe your friend; he says all sorts of stuff. So, you have a preconceived notion that this coin is probably fair. You assign a 90% probability to the coin being fair. Fair enough!
Now your friend knows that you tend to get convinced by the evidence. He asks you to toss the coin 20 times and make up your own mind. You agree, toss it 20 times and now it turns up heads 14 out of 20 times. Now what? Do you believe your friend that the coin is loaded? Let’s keep the model simple and avoid integrating over a continuous range of possibilities by assuming that the coin is either totally fair or loaded to turn up heads 75 percent of the time.
Now let Fair be the event that the coin is fair and Fourteen is the event that you observe 14 heads in 20 tosses. You initially thought that P(Fair) = 0.9 and P(Loaded) = 1 – P(Fair) = 0.1 and but you know Bayes’ theorem, you know that

So, the probability that the coin is fair has to be revised after observing Fourteen. Our prior probability gets multiplied by a ratio. The numerator of the ratio is P(Fourteen|Fair), that is the probability you will observe fourteen heads out of twenty given a fair coin. Thankfully this is easy to compute given it follows the binomial distribution. (You can read about it here, but it isn’t necessary to understand it for the purpose of this discussion)

But what is P(Fourteen)? that is the total probability of getting 14 heads out of twenty tosses. Well, there are two ways this could have happened, either the coin was fair and we observed fourteen heads out of twenty tosses, or the coin was loaded and we observed 14 heads out of twenty tosses. In both cases it is possible to observe 14 heads! Just with different probabilities.
So,
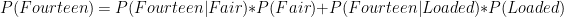
This is the law of total probability. Again, from the binomial probability distribution, P(Fourteen|Loaded) = 16.9% and from the law of total probability,
P(Fourteen) = 0.037 * 0.9 + .169 * 0.1 = 0.05
Therefore, you need to adjust your probability that the coin is fair!
P(Fair|Fourteen) = 0.9*0.037/0.05 = 0.667
And voila, from being 90% sure, you are now only 66.7% sure that the coin is Fair! Just after a simple experiment, you have to change your preconceived notions.
Well what if you hadn’t observed 14 heads? What if you had observed 13 or 15? Well, with a few short lines of Python, you can graph how the evidence changes your Posterior probability, despite the Prior probability (preconceived notion) of the coin being fair.
from scipy.stats import binom
import numpy as np
p_fair = 0.9
p_loaded = 0.1
outcomes = list(range(0,21))
# Get the probability of 0 - 20 heads in a trial given
# the coin is fair
p_outcomes_given_fair = binom.pmf(outcomes,20,0.5)
# Get the probability of 0 - 20 heads in a trial given
# the coin is loaded #to give heads 75% of the time.
p_outcomes_given_loaded = binom.pmf(outcomes,20,0.75)
p_outcomes = p_outcomes_given_fair * p_fair + p_outcomes_given_loaded*p_loaded
p_fair_given_outcomes = p_fair * (p_outcomes_given_fair) / p_outcomes
#Draws the plots
ax = sns.lineplot(x = outcomes, y = p_fair_given_outcomes)ax.
set_ylabel('Probability of coin being Fair')
ax.set_xlabel('Number of Heads in twenty tosses')
ax.set_title('Loaded at 75% heads or Fair?')
And there you see how evidence impacts your preconceived notions. This is what I love about Bayes’ theorem.
So, if you believe X is true and Y happens which is very unlikely to happen if X is true but quite likely to happen if X is false, you reset your mental probability of X being true! Plus, it is iterative, you can keep changing your mind as new evidence is presented.
Let’s take the same approach to climate change or COVID19, I understand it is hard to believe outright that the climate is changing due to our actions or that there is a killer pandemic out there, our brains want to believe differently, that things are okay, but let us change those beliefs when presented with evidence. If you’d hang on here for a little while more, we’ll apply this theorem to climate science, and think a little. We know that 97% of climate scientists agree that anthropogenic climate change is happening.
Let NinetySeven be the event that 97% of climate scientists agree on anthropogenic climate change, and ClimateChange be the event that anthropogenic climate change is occurring. Then using our previous formulae,

Of course, we can only wonder about the probabilities here, but even if you are initially skeptical about climate change, assigning it a 20% probability of happening.
What do you think the probability is that ninety-seven percent of the world’s scientists would agree that it is happening, given it is actually happening. Let’s say you doubt the scientists’ ability to accurately measure climate change and hence assign only an 80% probability, that they would agree it is happening, given it is happening.
More interestingly, what do you think the probability is that ninety-seven percent of the world’s scientists agree on climate change happening, when in fact it is not! That seems absurd! But even if you think that would happen 10% of the time. (I find that unlikely, but I’ll be generous). You now have to revise your prior belief to
P(ClimateChange|NinetySeven) = 0.2 * (0.8)/(0.8*0.2 + 0.1*0.8)
= 0.67!
So now you at least have to be on the fence about climate change, and then you can read up more and revise your belief as you encounter more evidence.
In real life, we’ll only have guesstimates for a lot of these probabilities, but think about this, every time you hear a conspiracy theory they try to claim that there is a large probability that the evidence is manipulated, that massive amounts of evidence exists despite the hypothesis being false, and this is a result of some large scale coordinated effort. Think about the probability that this could be true, for eg: That 97% percent of the world’s scientists were coerced into claiming a falsehood is true, if there isn’t a good explanation (with evidence) for how this could be, then the skepticism is just denialism.
I’ll leave this discussion here, there can be more said about what evidence is real or good. Should I believe everything I see, but that is another topic.
Do check out this article for a beautiful Bayesian argument for anthropogenic climate change.
— author, Gowri Thampi
In The United States, public opinion is viewed along a left-right spectrum. We expect certain beliefs to coexist, for eg: Denial of climate change, adherence to a certain faith. The objective is to test out this theory by using real world data across US counties. Is opposition to prioritizing the environment over the economy, correlated with adherence to evangelical Christianity. Geopandas and Leaflet are used to read in county boundaries as polygons and plot them on a map of the world.
Disclaimer: The objective of this analysis is not to cast adherents of any faith in a particular light but to test out commonly held notions about the coexistence of such beliefs.
There are three plots in the analysis, on a 2*2 grid. The first and third plots are intended to give a geographical visualization of the variables (percentage of respondents opposed to prioritizing the environment over the economy) and (number of adherents of evangelical Christianity per thousand residents).
The third plot is a scatter, of these two variables, with each point representing a county. From the geo plots we can see that evangelical Christianity is particularly popular in certain regions of the United States, particularly the southeast. Opposition to giving priority to the environment is however more dispersed geographically. though the southeast states show heavy opposition too. From the scatter, we can see that, though low and high rates of opposition to prioritizing the environment are found across all counties, counties with higher evangelical Christian adherents only show high rates of opposition. This is a nuance uncovered by the analysis, opposition to environmentalism comes from those with other beliefs as well, though there is scarce support for environmentalism in counties with a high rate of evangelical Christianity adherents. Note: a few counties have more than thousand adherents per 1000 residents, among other reasons this could be because of a large city situated at a county boundary, where residents of the city cross the boundary to worship.

Sources for Data:
1) County polygons, United States
https://eric.clst.org/assets/wiki/uploads/Stuff/gz_2010_us_050_00_500k.zip
2) Climate Change Opinions – Yale climate opinion maps 2018
Variable used- prienvOPP
https://climatecommunication.yale.edu/visualizations-data/ycom-us-2018/?est=happening&type=value&geo=county
3) Religiosity – The association of religious data, archives, US Religious Census, Religious congregation and membership study 2010. Variable used: EVANRATE
http://www.thearda.com/Archive/Files/Downloads/RCMSCY10_DL2.asp
4) US county FIPS codes
https://www.nrcs.usda.gov/wps/portal/nrcs/detail/national/home/?cid=nrcs143_013697
5) US state abbreviations – 2 digit
https://cdiac.ess-dive.lbl.gov/climate/temp/us_recordtemps/states.html
(I talk about little insights or aha moments I’ve had while learning concepts, the concepts themselves may be learned from sources far wiser than me, so I do not try to be comprehensive, instead I prod you to think by presenting the crisp little joyful moments of clarity I’ve had and invite corrections of my thought process)
Talking about the central limit theorem, I encountered this theorem many times while studying probability and statistics, without quite understanding it and as a result having a fundamental lack of clarity when it came to hypothesis testing. Why are we using the normal distribution to talk about average number of heads in a series of coin tosses? What is so ‘normal’ about tossing a coin. What about those light bulb failure rates? Why are they so faulty and how do I know they all fall in a bell curve, maybe the distribution of time to failure looks like a dinosaur tail, why a bell curve? Maybe I should just get a beer.

So today, we’ll understand a few things about the central limit theorem, twiddle around with it, with our own hands, and as a result understand a thing or two about hypothesis testing. There are many versions of this theorem, but I will restrict this discussion to the classical central limit theorem which talks about the mean of independently and identically distributed random variables. For a large enough number of such random variables, their mean will approach a normal distribution.
Before talking about what the parameters of the distribution would be, I’ll talk about the beauty of this which makes it so applicable to a wide range of problems. Remember the dinosaur tail looking distribution of time to failure for light bulbs? That may actually be so! but if I sample enough such light bulbs, the mean of their failure times, will lead to a normal distribution. The same with the average number of heads in a sample of coin tosses. You can see at once, how the convergence of all these distributions into the normal distribution is at once, frightfully wonderful and useful.
To be a little more specific. If we sample from a distribution any probability distribution, with mean 


So we already get an idea of how this may be useful in testing hypotheses, given that the normal distribution is well understood (as compared to dino tails) but before delving into that. Let us play around with what we know. Observe, tinker, be silly. The jupyter notebook in the link below allows you to simulate the toss of a coin and observe how for larger sample sizes, the number of heads in a sample approximates to the well known bell curve. (The distribution of the sum of heads in a sample approaches a normal distribution as the sum is a constant times the mean. This concept, called the normal approximation to the binomial distribution can be explored in detail in the sources below.)
Press the play button on the left of the notebook cell to run the tool and observe the animation.
(Opens in a new tab, give it a bit to load the environment)

(Alberto Cairo’s paper Graphics Lies, Misleading Visuals Reflections on the Challenges and Pitfalls of Evidence-Driven Visual Communication gave guidance to the below analysis)
Humans love visual representation of data. A computer may look at long rows of data, or unstructured data even, and draw insights from it. For us humans though, that information needs to be presented as graphics we can understand, often with various shapes and colors added to drive home a key point. While I’m all for making information and trends visually insightful to humans, we must proceed with caution as often such representations can be misleading or downright dishonest. I highly recommend reading Cairo’s paper to gain a deeper understanding of this problem.
Here, I’d like to provide a quick analysis of a graph I saw on a medium article titled ‘Why We Need to Recognize and Consider Organic Foods’ .

[1] https://medium.com/@mcmahonadam2/why-we-need-to-recognize-and-consider-organic-foods-f127f69261df
I’m leaving out the statistical information on the top of the graph, including debates on the relevance of p values and R square goodness of fit values, or even the fact that correlation doesn’t imply causation, to focus simply on the visual deception of the graphic.
The deceptive tricks used fall into two categories:
The graph proclaims to plot two different correlations:
between glyphosate usage and death rates from end stage renal disease
between the percentage of US corn and soy crops that are GE and death rates from end stage renal disease.
What does it show in reality though – Three data time series superimposed on each other at the same time.
Note how the x axis is time, meaning the graph doesn’t show the correlation between any two series, instead it simply shows how three different series of data are correlated with time!
Need I point out how the series all start at different points in time. For eg: Death rates from renal disease are plotted from 1985 to 1991 even though there is no information plotted about the supposedly causal glyphosate usage and percentage of soy and corn crops that are GE.
Now look at the Y axes.
For one, they are both truncated, also why are there two axes ? Is there a third axis for the % GE Soy and Corn series.( btw how does the same percentage apply for soy and corn)
Truncating the Y axis helps to magnify and hence distort the magnitude of change in a series.
For a series(40,50) let’s say if the y axis is truncated at 40, the point with value 50 would look like infinite growth from the previous point!


Including multiple y axes in data is a way to suggest correlations or superimpositions in values that don’t really exist. If I’m allowed to change the scale of the y axis and its origin, I can make almost any two series look like they correlate.
To illustrate, I constructed two series of numbers random 1 and random 2, with 1 data point each from 1991 to 2009, both series are the sum of a random number and a linear time trend.

In the above figure, the two series are plotted against time, with a common Y axis starting at the origin 0.

Above, I’ve included two y axes with truncated origins.

Hid some of the values of Random1 above, overall suggesting to a user at a first glance that the sudden occurrence of the blue line caused the changes in the orange line.
So, in conclusion, graphs are great, but they are worth pondering over beyond the initial aha moment they might create in us.