(I talk about little insights or aha moments I’ve had while learning concepts, the concepts themselves may be learned from sources far wiser than me, so I do not try to be comprehensive, instead I prod you to think by presenting the crisp little joyful moments of clarity I’ve had and invite corrections of my thought process)
Talking about the central limit theorem, I encountered this theorem many times while studying probability and statistics, without quite understanding it and as a result having a fundamental lack of clarity when it came to hypothesis testing. Why are we using the normal distribution to talk about average number of heads in a series of coin tosses? What is so ‘normal’ about tossing a coin. What about those light bulb failure rates? Why are they so faulty and how do I know they all fall in a bell curve, maybe the distribution of time to failure looks like a dinosaur tail, why a bell curve? Maybe I should just get a beer.

So today, we’ll understand a few things about the central limit theorem, twiddle around with it, with our own hands, and as a result understand a thing or two about hypothesis testing. There are many versions of this theorem, but I will restrict this discussion to the classical central limit theorem which talks about the mean of independently and identically distributed random variables. For a large enough number of such random variables, their mean will approach a normal distribution.
Before talking about what the parameters of the distribution would be, I’ll talk about the beauty of this which makes it so applicable to a wide range of problems. Remember the dinosaur tail looking distribution of time to failure for light bulbs? That may actually be so! but if I sample enough such light bulbs, the mean of their failure times, will lead to a normal distribution. The same with the average number of heads in a sample of coin tosses. You can see at once, how the convergence of all these distributions into the normal distribution is at once, frightfully wonderful and useful.
To be a little more specific. If we sample from a distribution any probability distribution, with mean 


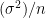
So we already get an idea of how this may be useful in testing hypotheses, given that the normal distribution is well understood (as compared to dino tails) but before delving into that. Let us play around with what we know. Observe, tinker, be silly. The jupyter notebook in the link below allows you to simulate the toss of a coin and observe how for larger sample sizes, the number of heads in a sample approximates to the well known bell curve. (The distribution of the sum of heads in a sample approaches a normal distribution as the sum is a constant times the mean. This concept, called the normal approximation to the binomial distribution can be explored in detail in the sources below.)
Press the play button on the left of the notebook cell to run the tool and observe the animation.
(Opens in a new tab, give it a bit to load the environment)