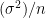How early stopping with LightGBM helped me predict who survived the Titanic disaster with >80% accuracy.

Predicting who survived the Titanic is a well-known machine learning competition on Kaggle.
The problem provides data for each of the passengers on the Titanic, their Age, sex, the class they travelled in, the port they embarked from, the fare they paid for their ticket, the number of family members they had travelling with them etc and requires us to build a model to predict whether the passenger survived.
I started out with it as a beginner to competing in Kaggle, and I used a tree based, ensemble model in my solution as they are well known to give good results in machine learning competitions. In particular, gradient boosted machines like xgboost and lightgbm work very well with tabular data.
In this post, I am not delving into exploratory data analysis for the problem because it has been done really well by a lot of datascientists, I’ll link to a few of them here. Instead I will talk about how I started off by heavily overfitting my model and how using early stopping with LightGBM helped me get a good fit and score within the top 8% of submissions. There were a couple of places where I felt I could squeeze out a little more accuracy, but at some point we need to move on and learn more.
What is LightGBM ?
LightGBM is an ensemble model of trees (weak learners) which uses gradient boosting to form predictions. You can learn more about gradient boosted machines, including xgboost on Statquest Josh Starmer’s amazing youtube channel. Here’s the link to the original LightGBM paper.
To summarize, gradient boosting uses a series of trees. First, a base learner makes a single prediction for the entire dataset, and then each tree that comes after builds on the residuals (errors) of the previous tree. A constant learning rate is used to proportionately add up the predictions from each of the trees.
Gradient boosting is an excellent technique that has reaped great results in the few years since its inception. However, it is prone to over fitting. LightGBM provides an array of techniques to prevent overfitting. Eg: restricting the depth of each tree, the number of leaves in the tree, the number of trees in the model, the number of bins over which efficient splits are searched for etc.
When I built my model, I realized that the Titanic dataset was inherently noisy, there is no way the data could give a perfect prediction of who survived the disaster, luck invariably played a factor. I knew that it was likely my model would fit noise. Hence I used many of the hyperparameters to perform a gridsearch within cross-validation folds. However, I wasn’t reaching a satisfactory accuracy. That is when I realized, that I was building at least 50 trees in each of my models. The default for the number of trees parameter was 100 and my grid was searching among 50, 100, 150 trees. It turns out I needed way fewer trees! I wouldn’t have realized this from my grid search alone. This is where early stopping comes into play.
Early stopping essentially tunes the number of trees/number of iterations parameter for you. The crux of the technique is, LightGBM after asking for a validation dataset, offers to stop building more trees once the metric of interest (accuracy in this case) stops showing an improvement after a specified number of iterations. The icing on the cake is, early stopping also returns the best iteration (number of trees for which the validation set gave the best metric score) even if this iteration happened earlier than the number of iterations required to trigger early stopping. So, if I had set early stopping to 100 (like I did) LightGBM would perform 100 iterations for sure before invoking early stopping, that is stopping the process when improvements fail to occur. However, if the best iteration was at 20 trees. LightGBM still stores this result and lets me know!
Through this, I realized that I was heavily overfitting my model and with a large enough learning rate, I needed only two or three trees! My dataset was indeed much smaller (892 rows) than what LightGBM was built for. Once I severely cut down the number of trees, I got a greater than 80% accuracy in the contest and was among the top ~8% submissions.
My code is available here on github.
You can see in the figure below, how the training set accuracy keeps increasing with the number of trees, but the cross validation accuracy drops steeply after the first few trees. This is classic overfitting, a machine learning algorithm fitting to noise and thus giving poor generalization.
I hope you can learn from my experience.


The same graph as above with an untruncated axis, That little decline you see in the crossvalidation dataset, takes you several thousand points below on the leaderboard 😀
— author, Gowri Thampi





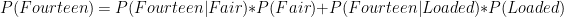




 variance
variance  , then as the sample size
, then as the sample size  increases, the mean of the sample tends to a normal distribution with a mean
increases, the mean of the sample tends to a normal distribution with a mean